Technical Blog Vol. 2
Timothee Hunter,
Christian Lessig
Running EU-wide Deep Learning projects for Weather
The WeatherGenerator project is an ambitious Europe-wide project to build a “Large Language Model for the weather.” From the outset, this leads to a very practical challenge: how to coordinate the development of a state-of-the-art model across 6 High Performance Computing (HPC) systems and 10 research groups? Each HPC system is custom built with the purpose of maximizing processing power at the expense of ease of use or convenience. This experience is very different compared to using a public cloud such as Amazon Web Services, Azure, Google Cloud. Public clouds are meant to be cost effective to build and operate. They are the Ford T’s of large computing: easy to use, simple, adapted to many scenarios. Public cloud operators put a large focus on standardization and automation as well as ease of use for the final customers.
This post presents some lessons learned from building and training models across so many HPC environments. We hope to provide some guidance to other large scientific collaborations using European HPCs.
The access matrix
The training of a Machine Learning (ML) model must bring people, data, and computing power together. This sounds obvious, but constraints immediately emerge:
-Each team only has access to a subset of HPC systems.
-Each HPC hosts a subset of the datasets. This is due to multiple reasons. The total dataset size for training weather models is beyond a petabyte. To compare, the dataset used for a modern LLM is around 10TB, a hundred times less. At this scale, simply transferring and storing data is a challenge. The storage costs also become prohibitive when multiplied by the number of HPCs.
Many local research institutions have created tools for their specific needs, and each HPC has slightly different configurations. Not only are the machines different (different amounts of memory, GPUs etc.), but simply connecting to them is also different! Some of them allow connecting to the internet, some others only allow secure shell (SSH) access, and so on.
Our guiding principles
How do we apply extreme open sourcing in such an environment? We were guided by the following principles in building our European HPC solution for machine learning.
-make simple tasks easy, make hard tasks possible: the infrastructure choices are made to accommodate the most common workflows. The researchers who investigate more exotic cluster configurations can still rely on the other pieces of infrastructure.
-centralize as much as possible: working as much as possible on shared tools means that we are speaking the same language as much as possible. We share the same documentation system, code control, ticket tracking system, etc. even if the compute resources are different.
-centralization yes, federation no: apart from the largest datasets, all inter-cloud operations happen through a centralized system. The models shared between teams are stored in a central S3-style storage bucket, not transferred directly between clouds. This has many benefits: we do not need to develop a matrix of connections between each of the HPCs, the central systems give excellent control and visibility. Additionally, we know how many models have been trained and run from all these resources.
-abstract the differences: for example, all datasets are stored in a single directory on each HPC system, and the HPC-specific directory is abstracted in a central configuration file. We simply agreed on a codename for each HPC (lumi, leonardo, …) to identify them uniquely, and a function provide the HPC-specific configuration
-one team philosophy: we abstract as much as possible the differences in working together. On top of more formal monthly stakeholder meetings, we embraced virtual daily standups between virtual teams. We share work on a single public issue board on Github. We perform quick retrospective and task planning together on a weekly basis. This is shorter than standard sprints in software development, but it helps create a stronger focus.
Compared to industry development teams, the WeatherGenerator team is more loosely tied and relatively autonomous. Development velocity is more sensitive to the strengths of individuals rather than sub-teams. This increases the risk of delays due to unavailability of authors or reviewers. All team members learn to make honest assessments about their capabilities and capacities and once committed to a task, dedicate sufficient time to seeing it through within agreed timelines. Timely communication and an open culture of discussing issues are critical for fostering a positive collaboration. When team-wide issues happen (for example when we need to roll back changes), we strive at fully analyzing the process without blaming or assigning individual responsibility. Any collaboration issues have been solved informally rather than being pushed through a more formal process.
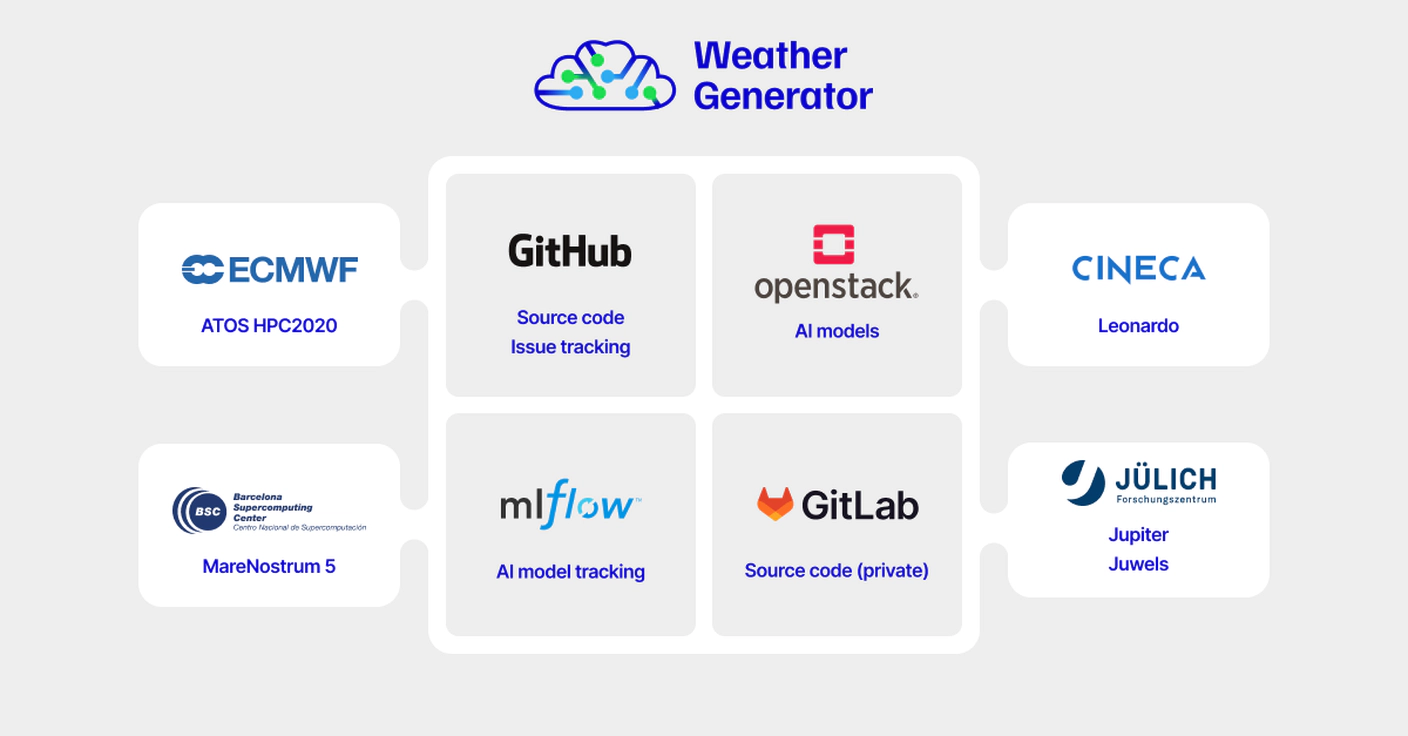
We adopted the following central services that mediate all interactions between the HPCs hosting the data and running computations (see image)
Using the central services is opt-in. Researchers can make multiple runs or iterate locally on their code within an HPC. When they are satisfied with sharing their results (a model, the metrics etc.), they push all the artifacts of that specific training run. With a single command, the metrics, the model weights, the various log items get pushed to an S3 bucket, MLflow, and so on.
These centralization efforts are starting to pay off. For example, one of the clusters was busy with large experiments, preventing the team from running training runs during that time. We were able to immediately launch these runs on a different cluster with no change in the code. Using a centralized dashboard, we can check if the same code running on a different HPC leads to similar performance.
Lessons learned
We hit a few surprises along the way:
-When IT budgets are tight, Github can be very expensive. Registering everyone from the project as guest contributors for ECMWF meant large fees on Github. Not doing it still allows developers to contribute (we are open source), but we cannot assign tasks to people. The compromise was to add one person per team who is pinged if necessary.
-The long quest to replace Google Docs. Being a virtual team across multiple research organizations, we had to search intensively for a Google Doc alternative hosted within the EU. Corporate subscriptions from Microsoft Sharepoint do not usually allow external parties to be granted rights to specific folder or directory. Many open-source alternatives did not pass the bullet train test: editing an online document over a flaky connection on a high speed train (a travel necessity in Europe) presents no issue to Google Docs or Microsoft SharePoint, but it has destroyed documents on other less mature systems.
-naming: as mentioned, agreeing on names and detecting the various HPCs is critical for automation, and yet no one was aware of an existing solution. We developed a set of tools to identify the clusters being used at run time and dynamically load cluster-specific configuration files.
-no common way to distribute and manage secrets. Public clouds have highly secure and sophisticated APIs to manage secrets such as access tokens, passwords, etc. No such system is used widely in HPCs. Most commercial offerings assume a connection to the internet, but this is not a given in an HPC. As a result, we store our secrets in carefully audited configuration files.
Thanks to all these choices, we can collaborate relatively seamlessly between all organizations. This has had a very positive impact on team productivity, allowing us to quickly iterate on model choices.